A blog post by Fatih Ozturk & Fatma Sen
Policy and claim file details are the most important datasets insurance carriers collect over the years. Policy datasets have dozens of features that contain important information like policy start/end dates, building info, location, premium, and other descriptive points that define risk. Claim datasets describe the events that caused damages to the covered entity and their financial outcomes. Building a predictive model using these datasets only usually fails to predict the likelihood of a claim for a given policy. Having flood claims in a region doesn’t mean that region has a statistically significant high flood risk as just not having flood claims in a region doesn’t mean that region has a statistically significant low flood risk. This is one of the simplest reasons for insurance carriers to use external datasets that could explain different phenomena (cat and non-cat events).
Not all claims are created equally
Claim prediction models cannot be as successful as labeling an image as ‘cat’ or ‘dog’ due to the nature of events that causes claims. All events have unique outputs and even the same type of events (e.g. floods) can have different underlying causes and entirely different outputs based on time, location, and infrastructure. Therefore, having only building related features and city/district information is not sufficient for satisfactory predictive power.
As UrbanStat has been targeting P&C lines that focus on buildings and liabilities caused by events that affect buildings, or their users, it only makes sense to use more ‘spatial’ features that can add further value against damage types.
Types of external datasets
At UrbanStat, we use datasets from 2 different type of sources:
- Private data partners
- Public organizations
Before we decide on which datasets to use for an insurance carrier, we do a preliminary analysis on claim distributions. For example, in Florida, most of the damage types belong to water-induced and wind-induced causes. So we pay more attention to sourcing risk datasets related to water, flood, storm, and hurricanes. On the other hand, when looking at other regions these datasets are not as useful, so our focus is on snowfall, hail, and storms when it comes to modeling in Massachusetts.
Bringing in more datasets doesn’t guarantee the success, cleansing and processing those datasets are equally important. Before doing any kind of modeling, we focus on data cleansing and derivative data creation. For example, FEMA Flood Maps may have topographic errors or erroneous inputs but doesn’t require creating derivative datasets.
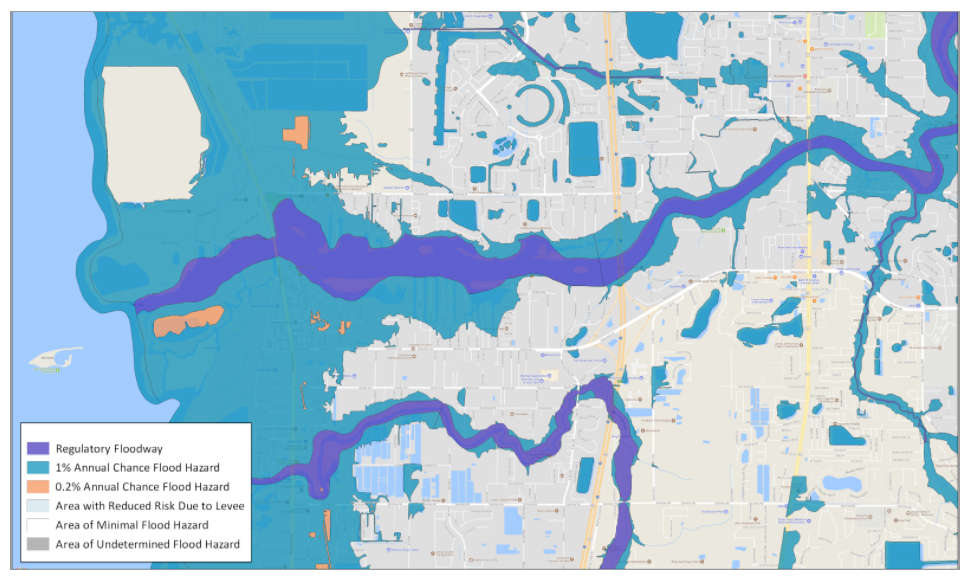
City of Tampa, Florida – FEMA Flood hazard map
Shoreline data itself doesn’t explain anything but by creating proximity maps as seen below we added enormous value to the claim prediction.
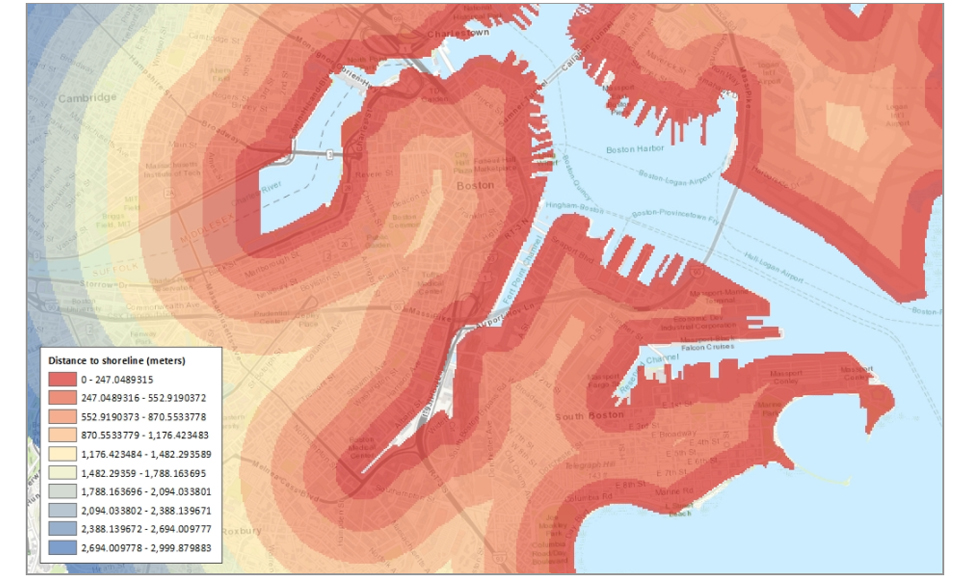
City of Boston, Massachusetts – Shoreline Proximity Map
Getting an edge
We have seen remarkable differences in our models when we used external datasets. While it is really hard to have financially successful prediction results with datasets only provided by insurance companies, adding external datasets give much better prediction results and hence satisfactory financial improvements. Historically, 70 out of top 100 important features having an impact on financially successful predictions are actually the features UrbanStat has engineered.
Conclusion
The importance of bringing in new datasets in claim prediction is but one piece of the puzzle, really digging in and understanding which datasets can provide the most value for a specific purpose and then have the expertise to frame, build and design prediction models for each use case is where real impact occurs and where unexpected results are discovered. UrbanStat has continued to refine its models for all types of global geographies and business lines and continues to produce actionable results for its partners.
To learn more and quickly leverage what we’ve already successfully deployed for our carrier partners contact us at [email protected].